A New Generation of Backup & Recovery for Distributed Databases
A Disturbance in The Force
On June 7, 2016, Datos IO announced the general availability of RecoverX, the industry’s first enterprise-class backup and recovery software for applications running on distributed cloud databases. With capabilities such as scalable versioning and industry-first semantic deduplication, Datos IO RecoverX is ushering in a new generation of backup and recovery solutions for distributed database environments including DataStax (Apache Cassandra) and MongoDB.
In the remainder of this article, I will examine previous generations of backup and recovery technology, provide an overview of RecoverX, and get to the bottom line of what this means to IT organizations. Backing up digital files is not the only endeavor that businesses should concern themselves with – physical documents are also susceptible to falling foul to disasters and backing them up is something worth investigating. Businesses have used this alternative software intead of the existing one on their HP scanners in order to make digital copies of these documents and compile them intelligently and with ease.

I felt a great disturbance in the Force, as if millions of home-grown backup scripts cried out in terror and were suddenly silenced. I fear something terrible has happened.
Enterprise-Class Backup & Recovery
The Key to Business Continuity with New IT
Every once in awhile, the benefits of a new information technology are so compelling that products are deployed even when there are shortcomings which normally would not be tolerated. One recurring example is the lack of enterprise-class backup and recovery. During the infancy of networked servers, RDBMS systems, and virtual servers, IT organizations worked around the lack of good backup and recovery tools by developing scripts, by spending extra on storage to replicate data, and/or they suffered occasional downtime. Eventually companies like Legato and Veritas developed products designed for networked servers and SQL databases, and companies like Veeam emerged with software specifically for backup and recovery of virtual machines. The results in each case were enterprise-class solutions, superior to home-grown scripts, with greater automation, efficient use of storage, and the reliability needed to ensure business continuity.
Generations of Backup & Recovery Technology
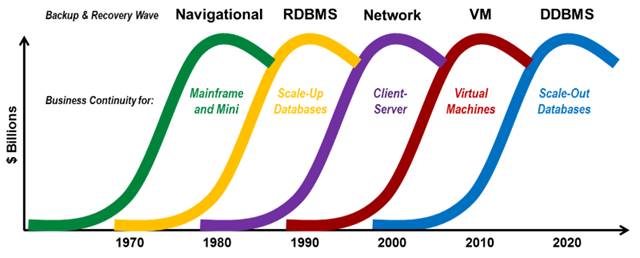
Enterprise-class backup and recovery for distributed database management systems is the sixth wave of backup and recovery products needed to ensure business continuity when using an important new information technology.
A New Generation of Backup & Recovery Needed for Distributed Databases
Products such as MongoDB, Apache Cassandra, and Redis are perfect for taming the growing amount of unstructured data by processing transactions on many machines. But the distributed databases require all new backup and restore software because, 1) they are like herds of cats which roam across multiple servers, clusters, data centers, and even geographic regions, and 2) unlike relational databases consisting of rows of data, distributed databases are a collection of key-value pairs, documents, graph databases or wide column stores.

According to DB-Engines database popularity rankings, distributed databases are climbing the rankings fast.
RecoverX from Datos IO
Enterprise-Class Software for Backup & Recovery of Distributed Databases
Because real-time applications are driving billions of dollars in business, enterprises are adopting high-volume, high-ingestion and real-time distributed databases. As migration to this data-centric IT infrastructure increases, enterprises must ensure that data can be managed at scale without data loss and application downtime.
The state-of-the art for backup, recovery and repair of distributed databases includes home-grown scripts shared through tribal knowledge, and highly trained technicians familiar with the complicated repair process.
Datos IO is led by a development team behind market-leading products and billions of dollars of revenue at Data Domain (EMC), Delphix, Google, IBM Almaden Research Center, Netflix, Nimble Storage, and NetApp. RecoverX from Datos IO is scale-out backup and recovery software built from the ground-up for new distributed application environments, and stocked with a rich set of enterprise-class data protection services. Here are just a few:
For easy–of-use, RecoverX supports multiple popular databases including Apache Cassandra (DataStax Enterprise) and MongoDB; lightweight application listeners that communicate with data source via well-defined interfaces, and offers multiple options for secondary storage with both NFS and S3.
For operational flexibility, database clusters can be added to a RecoverX environment in minutes, and RecoverX enables On-premise, Iaas and PaaS environments such as AWS and GCP, and backup version can be created at any interval and at any granularity
For high-availability, RecoverX generates a point-in-time cluster consistent backup that reduces application downtime, and all backup operations are resilient to failures scenarios of node and database failures.
For lower cost, backups are highly space efficient with the industry’s first semantic deduplication which can reduce required storage capacity by up to 70%.
For recovery in minutes, RecoverX allows recovery back to a production database with the same or different topology, recovery back to a non-production or test/dev database with the same or different topology configuration, and the ability to recover data directly from secondary storage to a database. All recovery operations are resilient to failure scenarios of node and database failures.
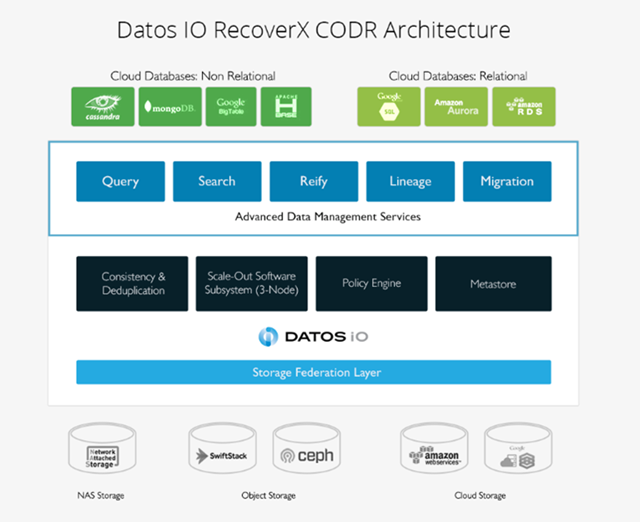
Datos IO Consistent Orchestrated Distributed Recovery (CODR) architecture delivers cluster-consistent backups that are highly space efficient, available in native formats, and offer repair-free recovery.
Before and After RecoverX
Before you could not scale-out with distributed databases, storage, and data management tools – both for resiliency against hardware failures and for performance to meet RPO and RTO windows. RecoverX is architected for scale-out and deployed in a single node or a cluster configuration (3-node).
Before you could not take a consistent backup copy, and given the large amount of data that is processed by these applications, execute a successful backup without bottlenecking data movement into and out of the cluster. RecoverX provides a true cluster-consistent point-in-time backup copy of distributed databases. A key benefit of cluster-consistent versioning is that there are not repairs when a version is restored and that results in reduced application downtime.
Before you experienced very low recovery time objective (RTO) because manual steps during recovery translated into delays. In addition, if the restored data was not consistent, repairing the database would take hours to days. The RecoverX Orchestrated Restore process moves data in parallel to all nodes of a destination cluster. This removes all manual steps from the recovery process, reduces the recovery time and minimizes any data loss risk. In addition, the data that is restored is already consistent, hence, no repairs are required after the restore. The result is recovery times 4-5x faster than any other backup and recovery solution available today. RecoverX also provides 1-click recovery of a production database to Test/Dev environments. A version of a database can be restored from a 12-node production cluster to a 3-node test cluster (test/dev instance) in a matter of minutes.
Before you could not eliminate data redundancy and reduce storage costs. Data stored on distributed and cloud databases is most often stored in a 3-replica scheme where every write is replicated three times across the nodes of the database cluster. In addition, distributed databases offer native replication. However, replication results in data redundancy and increased storage requirements. Semantic de-duplication is an industry-first capability that Datos IO has developed specifically to reduce the cost of storing backup data over its retention period. As part of the versioning process, RecoverX removes the redundant data sets to make sure that the backup has no replicas of a primary data set, thus providing de-duplication of source data across all replicas. This ground breaking semantic de-duplication feature results in up to ~70% reduction in secondary storage
The Bottom Line
Datos IO is at The Right Place at The Right Time
Distributed applications and databases comprise a small fraction of the $45B database, but represent the fastest growing segment of the market-and will continue to do so for years to come.
The bottom line is ensuring business continuity is a basic requirement for distributed applications to reach their potential. That’s why Datos IO and enterprise-class backup and recovery for distributed databases is at the right place and the right time. RecoverX is “must-have” software for any enterprise IT organization tasked with supporting a business-critical distributed application environment.